This article is tailored to your preferences. Simply choose the researcher profile that resonates with you the most, and enjoy a personalized reading experience.
Feel free to join the discussion section to exchange ideas and offer feedback. Additionally, you have the opportunity to propose edits to the article in the discussion or issue section, or even by submitting a pull request. Your input is valued!

Advancements in machine learning technologies have brought about a revolution in various areas of biomedical research, by using AI as a tool to facilitate advancing existing paradigms in the field. However, can the exchange of ideas between biology and machine learning work both ways? Can insights from biology prove beneficial in the field of machine learning?
Specifically, can we find powerful invariants across domains - principles of system-level function which help to unify phenomena that have, until now, been treated as disparate sub-fields
A highly related concept is that of collective intelligence and swarm cognition
One of the most interesting aspects of biology is morphogenesis - the ability of cell groups to harness individual cell behaviors into reliable construction, repair, and maintenance of complex anatomical forms. We have recently argued that it is empirically fruitful to view this process not merely as emergence of complexity but as a kind of behavior (in anatomical morphospace) of a collective intelligence of cells which is able to solve a variety of problems
This paper aims to showcase how the process of self-organization, observed in biological systems, can be harnessed to develop coherent narrative skills within linguistic space. By allowing words in a text to self-organize, a cohesive and meaningful whole can be created.
In textual context, words can organize themselves into sentences, which further organize into chapters, ultimately forming complete books, etc., as in biological organisms, cells organize into specific structures, which then combine to form organs, culminating in fully grown organisms and swarms
Certain machine learning algorithms, such as neural cellular automata, have shown remarkable ability to replicate aspects of the behavior of cells in biological organisms
Here, we demonstrate that attempting to teach a machine learning algorithm to generate text by simply providing each word with information solely from its neighboring words is unsuccessful in achieving self-organization. In this paper we will prove that this is due to the fact that text is a 1-dimensional sequence of words, and self organization in 1D is impossible. Biological organisms are 3-dimensional so don't have this problem.
We also show that, in principle, it is possible to generate long-coherent text by making distant elements of text interact via long range connections.
Furthermore we demonstrate that biological brains are likely incapable of retaining memories forever, and thus many species, including humans, have developed skills that allow them to store information for long term by interacting with the external environment.
Thus, interacting with the external environment is something that is indispensable for long-term storage for all living beings.
These results support the consistent patterns we discussed earlier, highlighting the need for systems trying to store memories or maintain patterns to put that information into their environment. This need arises due to limitations in their self-organizing abilities. Using a generic model we prove that a large class of self-organizing systems face fundamental restrictions on how long they can maintain coherence, and can escape these limitations by writing information to a static environment. We follow up with examples like stigmergy and the human brain which fall under the “universality class” of self-organizational behavior described by this model.
Why focus on text to study self-organization?
- Long-range cohesion is a necessary feature of text, and it is something that current language processing algorithms don’t possess. This will mean that any improvement on the theoretical front, will directly translate into an application in the field of natural language processing.
-
In text, spotting a misspelled word is easy. In biological (and virtual) organisms spotting an off place cell is hard.
This raises the bar of difficulty so it will give a more rigorous test on the ability of self-organizing systems - It’s easier to run experiments on code rather than biological organisms.
-
Since text is a 1-dimensional sequence it can give insights into other types of 1D sequences, for example a sequence of actions performed by an agent.
Having long term coherence for a sequence of actions performed by an agent means that the agent is able to stick to a plan and use information from the distant past to make decisions on what to do next.
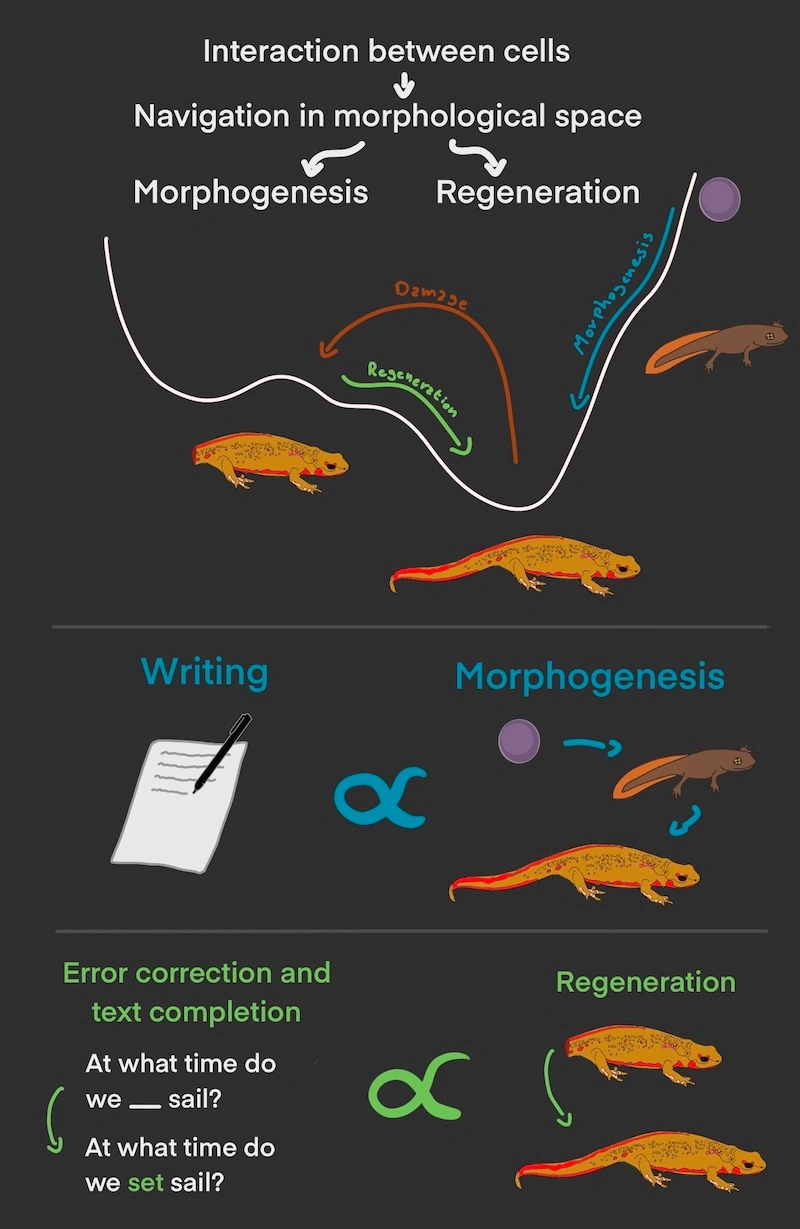
Many phenomena in self-organizing systems are interpreted in the literature as navigation in a morphological space.
In various fields like biology, linguistics and computer science, a morphological space refers to a conceptual space where each point represents a specific configuration or form of an entity. The term "morphological" refers to the form, structure, or shape of something.
Navigating a morphological space involves exploring and moving through this conceptual space to observe or analyze the different configurations or forms that an entity can take. It is often used to understand the relationships between different variations or possibilities within a system. Better configurations are associated with a lower energy value, and the system evolves rolling down this energy landscape.
One common example is in biology, where the concept of morphological space can be used to describe the range of physical forms that a species can exhibit
We propose that a number of biological phenomena, especially morphogenetic control, is a kind of navigation of a problem space (e.g., physiological, transcriptional, metabolic, and behavioral spaces)
Drawing parallels between text generation and morphogenesis, text generation starts with a prompt (analogous to an embryo) and progresses, generating the rest of the text until completion. Similarly, correcting errors in text, such as misspelled or missing words, bears similarity to the process of cell level defects, and repairing damage in the whole organism can be associated with keeping a conversation on-topic. Both tasks are error correction procedures that involve navigating a morphological space to rectify errors and achieve the desired final state.
Specifically, we are interested in discovering the architectures needed to facilitate the kind of collective behavior that enables efficient competency of the collective, and deploying them in other domains. For our test case of moving across domains and exploring plasticity, we examined the parallels between maintaining a trajectory in morphospace (reliably creating a complex anatomy in novel circumstances) and maintaining a trajectory in linguistic space (keeping the thread of a coherent narrative).
The simplest example of self-organization: The Ising Model
Initially, when students delve into the study of the Ising model, they often find it utterly useless and struggle to comprehend why physicists are so fixated on this seemingly mundane model.
The problem is that it's hardly ever mentioned that the Ising model is key to understanding how self-organization works. This is because the Ising model is the simplest example of self-organization. Thus if you want to understand how more complex self-organizing systems work you have to start by understanding how the Ising model works.
But what exactly is the Ising model? Originally conceived as a simple explanation for magnetization effects in matter, the Ising model explores the interplay between interacting spins. These spins, when in proximity, have a preference to align with each other, leading to an interaction energy denoted by $H=-Js_1\cdot s_2$.
What happens when lots of spins interact? Well, it depends on how they interact: The Ising Model comes in many different flavors, we are going to look at the 3 simplest ones: the fully connected, the 1D and the 2D one.
In the fully connected Ising model we have L spins, all interacting with each other. The Hamiltonian of the system is $$H=-\frac JN\sum_{i\neq j}s_is_j$$ Now let’s see how the system behaves as a function of the temperature.
As you can see, below a certain Critical Temperature $T_\textrm c$ you have an Ordered Phase, while above you have a Disordered Phase
In the 1D Ising Model, spins are arranged in a chain and interact with their neighboring spins. The system's Hamiltonian can be expressed as: $$ H=-J\sum_{i}s_is_{i+1} $$ Now, let's examine the behavior of this system in relation to temperature
As observed, regardless of how low the temperature is, the system never manages to achieve an ordered phase. This can be proven mathematically with the following theorem
TheoremThe 1D Ising chain doesn't have an ordered phase
proof
At thermal equilibrium, the Free Energy $F$ is minimized.
To demonstrate that the ordered state, where all spins align, is not the minimum of Free Energy, we have to examine what occurs when a domain wall forms.
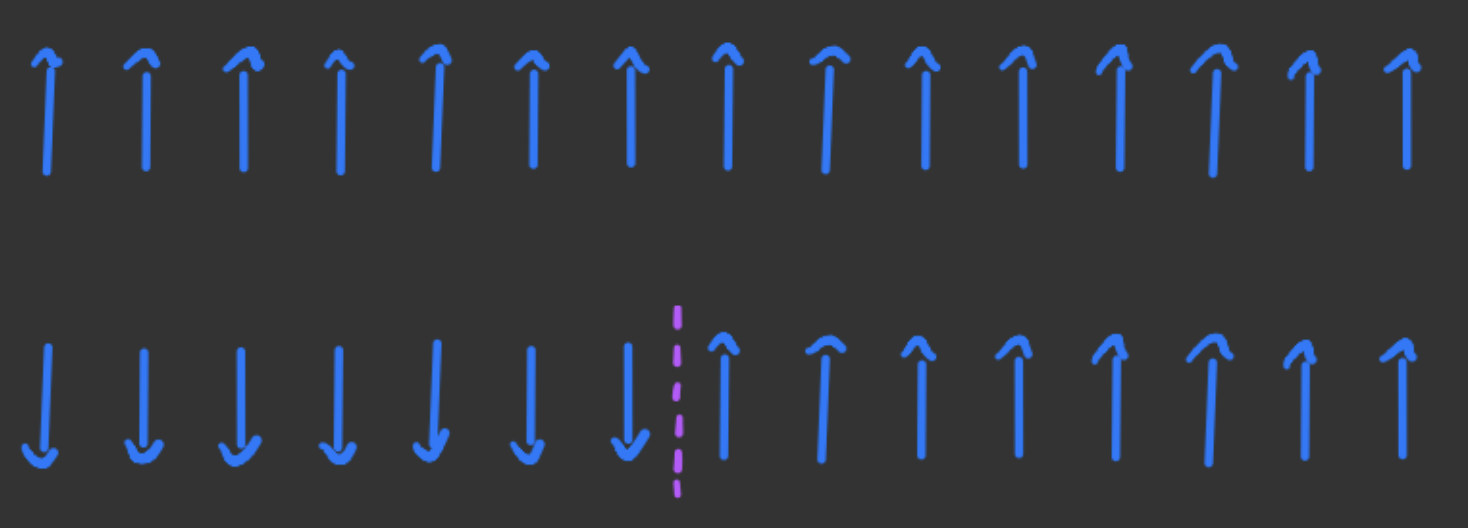
Upon the formation of a domain wall, the energy change increases by $2J$. This is because only a single link now comprises two opposite spins.
If the chain is $L$ spins long, there can be $L-1$ possible locations for the domain wall. Consequently, the size of the configuration space where a domain wall is present, denoted as $\Omega$, equals $\Omega = L-1$. Since entropy is the logarithm of the configuration space, we have $\Delta S = \log(L-1)$.
Therefore, the change in Free Energy upon the formation of a domain wall is given by:
$$
\Delta F= \Delta E -T\Delta S= J - T\log(L-1)
$$
In the thermodynamic limit, as $L$ approaches infinity, and since $J$ is a constant, we find that for any temperature $T$, $\Delta F < 0$.
Thus no matter how low the temperature (or the noise) is, it is impossible to reach an ordered state
In the 2D Ising model the spins are arranged in a grid, and each one of them interacts with his neighbors. The system's Hamiltonian can be expressed as $$ H=-J\sum_{\langle i,j\rangle} s_is_j $$ Where $\langle i, j\rangle$ means that we sum over all the neighboring spins. And let's see how it behaves
As you can see, when the temperature is sufficiently low, the system will slowly reach an ordered phase.
TheoremThe 2D Ising model does have an ordered phase
proof
The following proof is also known as Peierls Argument
Suppose we start in a configuration where all the spins are all in the $+1$ configuration, we now create a domain with a perimeter $\mathcal P$ made of spins in the $-1$ configuration, and see what happens to the Free Energy.
The change in energy will be $$\Delta E= 2J\times \mathcal P$$ Where $J$ is the coupling strenght between spins
The change in Entropy is harder to estimate, fortunately we only need an upper bound.
We need to find the number of domain with a perimeter $\mathcal P$.
We can always fit a curve of perimeter $\mathcal P$ inside a box $\mathcal P\times \mathcal P$ centered in the origin, so the number of starting points is at most $\mathcal P^2$, then at each step along the perimeter the curve has at most 3 choices for where to step next, so for each starting point there are at most $3^{\mathcal P}$ curves
We can thus conclude that the number of possible configuration $\Omega\le \mathcal P^23^\mathcal P$, and the change in entropy is $$ \Delta S\le \mathcal P\log3 +2\log\mathcal P $$ Putting it all toghether we have that $$\Delta F \ge 2J\mathcal P - T \mathcal P\log3 +O(\log \mathcal P)$$ And if $T$ is sufficently low we have that $\Delta F>0$, thus for low temperature the 2D Ising model at the equilibrium tends to an ordered phase.
However, there is a caveat here: The theorem doesn't tell us anything about how much time the system takes to reach equilibrium, in fact if the system is sufficiently large it can take more then the age of the universe. In this article we will not worry about the time it will need to reach equilibrium as this lays outside of the scope of this work.
If you want some great resources for learning about the Ising model and phase transitions in general I suggest you look at these books.
Ising model on a Tree
Many self-organizing systems seem to gravitate towards a hierarchical structure, in earlier sections of the paper we talked about how cells and words on the text organize into bigger and bigger structures. The same goes for how people organize into teams, companies, and so on.
So, let's take a briaf look at the Ising model on a Tree
Interestingly, the Ising model on a tree can be thought as a 2D Ising model in hyperbolic geometry, this means that the same proof for the existence of an ordered phase is pretty much the same as the one in the 2D case, but with the extra flavor of hyperbolic geometry.
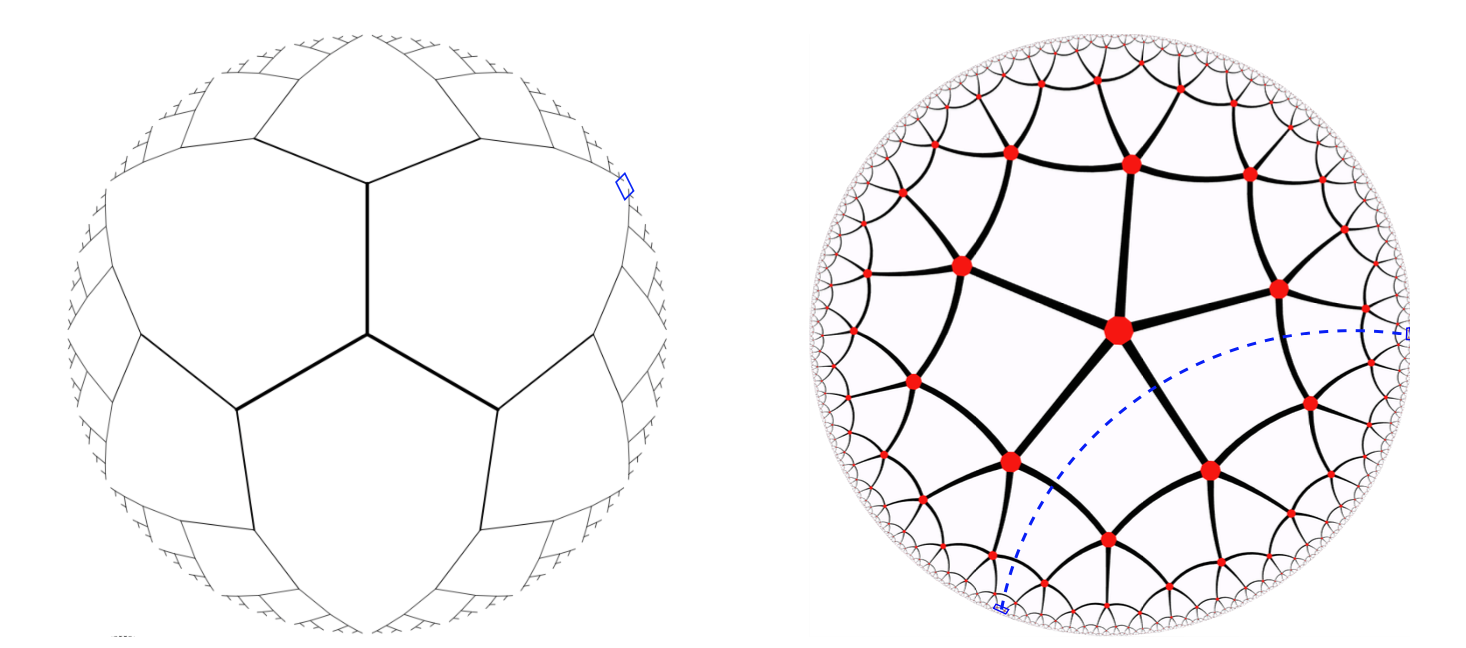

It does have the additional benefit that the average distance between a couple of spins in the same chain increases as $\log N$, so the information to go from one point to another needs to travel shorter distances.
We have seen that the ability of a self-organizing system to reach an ordered state can indeed be understood through the lens of phase transitions. In fact developmental biology has studied this phenomenon in the context of planar polarity of cells in a 2D tissue
When it comes to self-organizing systems, the concept of an ordered state typically refers to a highly organized and coherent configuration. For example, in the Ising model, an ordered state corresponds to spins aligning in a particular direction. In other self-organizing systems, it may involve patterns, structures, or coordinated behaviors emerging among the individual elements of the system.
Understanding the behavior of self-organizing systems in terms of phase transitions allows us to analyze their equilibrium properties, and gain insights into the underlying mechanisms driving the emergence of order. By studying the conditions and factors that influence phase transitions in self-organizing systems, we can better comprehend their ability to reach ordered states.
We will now give an overview of a more complicated self-organizing system through the lens of phase-transition: The Hopfield Network
The brain is capable of storing and retrieving memories, but the way it does that is very different from how the memories are managed in a computer.
- Address based memories, which are the kind of memories stored in a computer, work that given a memory address, it gives you back the information stored in that specific address.
- Associative memories are how memories are stored and extracted in human brains. In an associative memory system, when given an input, the system returns the most associated memory it has stored; furthermore a memory becomes easier to extract the more “hints” or related memories are given.
An example of associative memories are search engines. What a search engine does is to return the most associated results to the query given by the user.
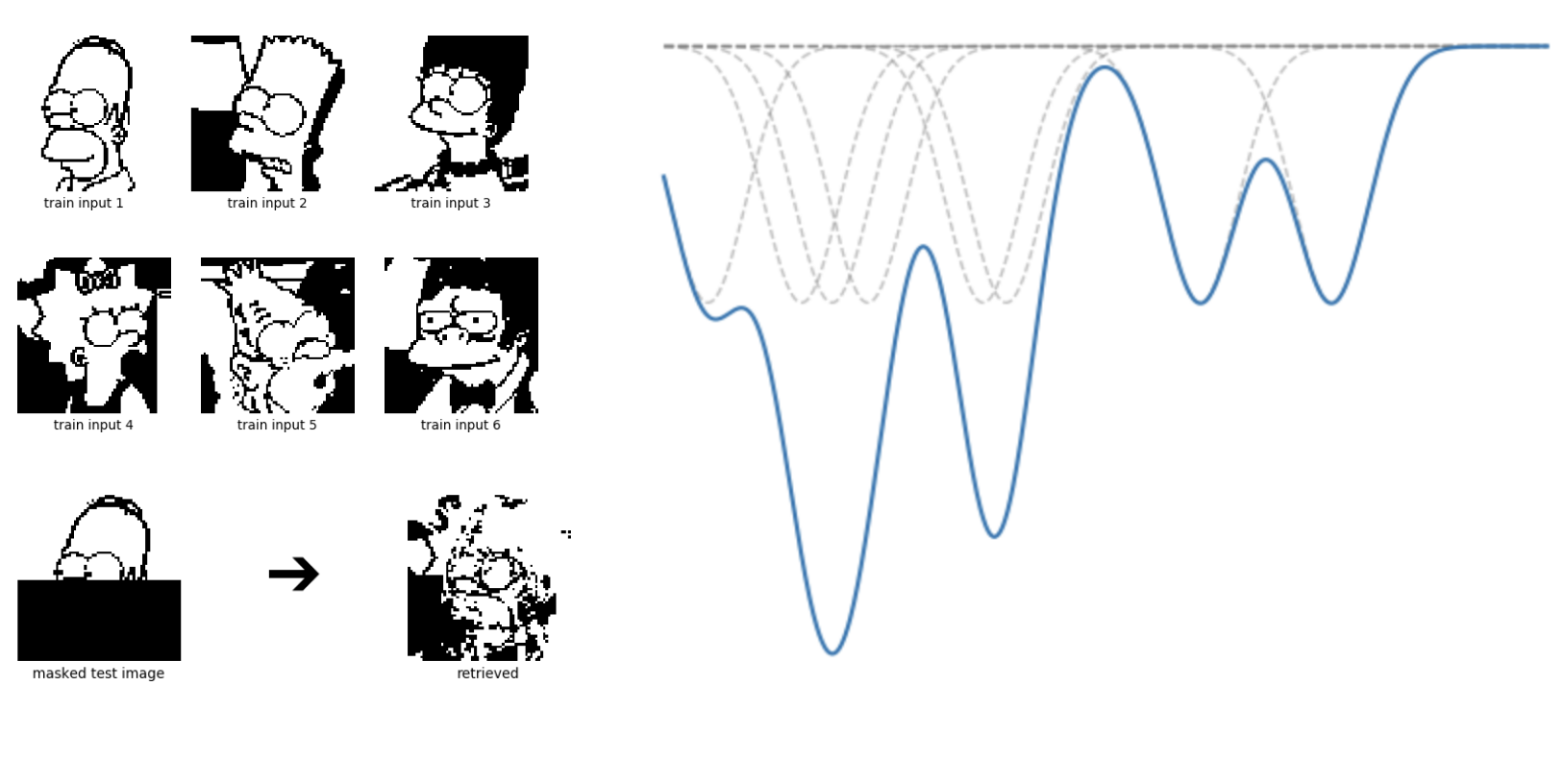
In general, a associative memory can be modeled as a energy landscape with with a discrete number of minima, each of which corresponding to a stored memory
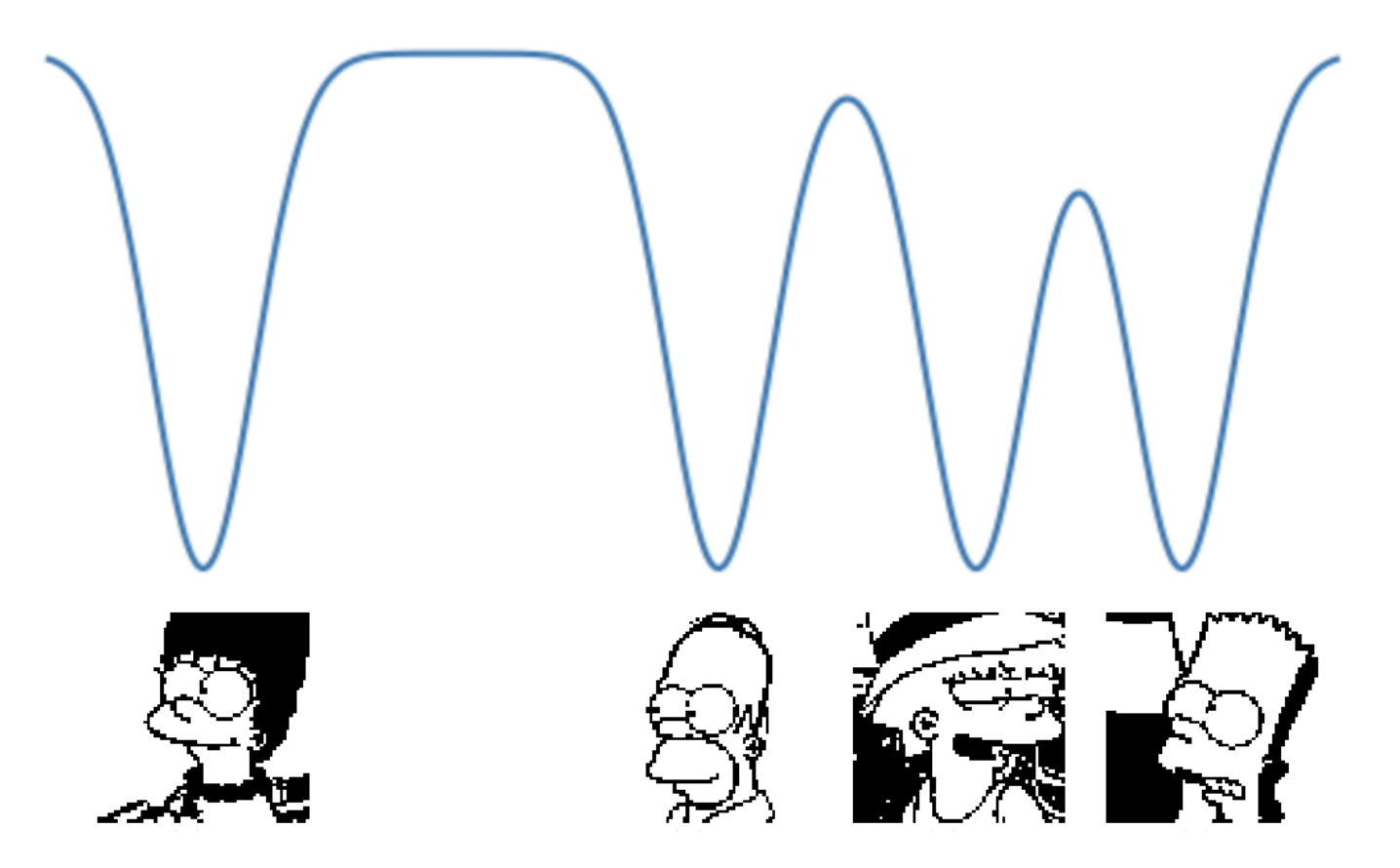
Associative memories, just like the memory inside a computer, have finite capacity. How do we quantify this?
Intuitively what ends up happening when you try to store too many separate memories, is that the configuration space becomes too crammed and some of the saved patterns fuse together.
Hopfield Networks
The standard Hopfield Network with $N$ patterns stored equation is the following
$$
H=-\sum_{ij}W_{ij}s_is_j\quad\textrm{ with }\quad W_{ij}=\sum_p^NX^p_{i}X^p_{j}
$$
Notice how this is similar to the equation of the Hamiltonian of the fully connected Ising model
You can go from a saved pattern to the other by increasing the temperature and relowering (it works 50% of the times). If you dont want to wait for the system to thermalize you can just reload the page.
As you can see at low temperature the system converges to the closest state, but at high temperature the system is noisy.
Many of the self-organizing systems in real life are capable of reaching a highly ordered state even with just local interactions, so what happens if the Hamiltonian of the Hopfield network makes spins interact only if they are close by? $$ H=-\sum_{\langle i,j\rangle}W_{ij}s_is_j\quad\textrm{ with }\quad W_{ij}=\sum_p^NX^p_{i}X^p_{j} $$ In this case $\langle i,j\rangle$ means that $i$ and $j$ are in the same window of interaction. Here is a simulation to play with.
As you can see the system struggles more to converge to one of the saved patterns, and the smaller the window size is, the harder it becomes.
What is possible to conclude even with this small demo is that the memory capacity of a local Hopfield model is lower, we will later analyze by how much.
So far we have seen that
- The 1D Ising model is not capable of self-organizing in to an ordered phase
- The 2D Ising model is capable of self-organizing in to an ordered phase, but it takes time
- The Fully connected Ising model is capable of self-organizing in to an ordered phase and it does that quickly
- The Standard Hopfield Network, which is a generalization of the Fully connected Ising model is capable of self-organizing quicky, but it doesn't have a large memory capacity
- Windowed Hopfield wich are a generalization of the 2D Ising model are in principle capable of self organizing, but their memory capacity is lower than the one of standard Hopfield Networks, and it takes time to self-organize
It turns out that a system can be capable of self-organizing if it is topologically equivalent to an Ising model which has a condensed phase at low temperatures.
It turns out that there is, but before proving in the general case, we will first prove why autoregressive models for text are incapable of generating text that remains coherent at arbitrary lenghts as it gives us the intuition to prove it in the more general case.
Topological requirements for self-organization
First, we generalize the value that the spins can take: instead of $-1$ and $1$, they can now take any integer value from $0$ to $V$
A Potts chain is $\mathcal C$ chain of spins $s_i$ with $i \in \mathbb{Z}$ and each $s_i$ can assume any integer value from $1$ to the vocabulary size $V$
Ok, now we are going to define how this new spins interact with one onother. We want them to interact with only their neighbours, thus only interactions inside a finite Window are non zero.
Definition: Hamiltonian WindowA Hamiltonian window $H_i$ is an Hamiltonian that acts only on the spins inside his finite window of interaction $\mathcal W_i$. Without loss of generality, we are going to assume that the lowest energy state has a value of zero.
Definition: Local HamiltonianA Local Hamiltonian $H=\sum_i H_i$ is an Hamiltonian that can be written as the sum of several windowed Hamiltonians $H_i$ all with the same window width $\mathcal W$. For sake of simplicity we are going to assume that there exists an upper bound to the highest energy of every windowed Hamiltonian $E^\textrm{max}_i < E^\textrm{max}$
As you can see this is a very general structure that can be used to model cells, agents, particles, and words arranged in a line or evolving though time.
Ok, now what is a memory in this kind of situation? A pattern stored is a particular configutation of spins with zero energy, or more precisely:
A stored pattern $\mathcal P$ is a particular sequence of spins $(\dots, s_{-1}, s_0, s_1,\dots )$ such that the energy of the Hamiltonian $H$ associated to this pattern is equal to zero. If more than one stored pattern is present, they can be numbered as $\mathcal P^{(n)}$ = $(\dots,s^{(n)}_1,s^{(n)}_0,s^{(n)}_1,\dots)$.
Notice how we don't really care what the spins represent: They can be the words in a text, or the state of the cells of an organism, or the actions performed by an agent, or the value of a title in the stock market.
We also don't really care how the values of the Hamiltonian are evaluated: The architecture of the model doesn't matter.
We are now going to prove that local Hamiltonians in 1D, no matter how low the temperature, cannot have a condensed phase.
TheoremLet $H$ be a local Hamiltonian with $N$ > 1 stored patterns. At non-zero temperature the system will be unable to converge to single stored pattern.
proof
Suppose that our Potts chain starts out equal to our first stored pattern $\mathcal C=\mathcal P^1$. Now we want to know if the formation of a single domain barrier is thermodynamically favorable. $$ \Delta F=\Delta E -T\Delta S< 0 $$ For that to be true, the Free energy of the system must decrease upon the formation of a domain barrier. Upon the formation of a domain barrier, The windowed Hamiltonians that intersect it will have a non zero, positive energy. Therefore $\Delta E >0$, however, we know that the energy of each window Hamiltonian is smaller than $E^\textrm{max}$ and no more that $\mathcal W-1$ windows can be affected by a domain wall, therefore $$ 0\le\Delta E\le (\mathcal W-1)E^\textrm{max} $$ At the same time we know that in a sequence long $L$ there can be $L-1$ possible places where a domain wall can appear, and for each of this possible places it can lead to any of the $N-1$ other patterns saved, therefore there are $(L-1)(N-1)$ possible configurations where the system has a single domain wall. This means that the change of the entropy of the system is $$ \Delta S=\log [(N-1)(L-1)] $$ Putting all the equations together we have that $$ \Delta F\le (\mathcal W-1)E^\textrm{max} - T\log [(N-1)(L-1)] $$ In the thermodynamic limit ($L\to \infty$) we have that the right hand side of the equation becomes eventually negative, therefore the domain barriers are inevitable.
We have now seen that 1-dimensional self-organizing systems can't really exists
Given some input tokens $\{s_{i_\textrm{first}},\dots, s_{i_\textrm{last}}\}$ an auto-regressive model $M$ return a $V$-dimensional $(p_1,\dots,p_V)$ vector with an estimate of the probability for the next element in the sequence $i_\textrm{pred}=i_\textrm{last}+1$ $$ p_c=M(s_{i_\textrm{pred}}=c|s_{i_\textrm{first}},\dots,s_{i_\textrm{last}}) $$ where $p_c$ is the porbability that the next spin $s_{i_\textrm{pred}}$ is equal to the $c$-th token of the vocabulary
We will now make the parallelism explicit with Natural Language Processing. Most state of the art language models of today are Autoregressive, meaning to predict the next word (or token) they look at all the previous elements on the text.
However, as the context increases, it becomes computationally infeasible to predict the next token, and only the last few words are fed as input to the model.
Intuitively, this leads the model to completely forget what is left outside of its input window
Keep in mind that how well you can predict the next element in a senquence can be considered a measure of intelligence. After all, what any intelligent agent does is just finding the best next action.
But how do we prove mathematically that autoregressive models with finite context are bound to lose the thread?
We show that Autoregressive models, no matter the architecture, are equivalent to a thermodynamic system with a specifically crafted local Hamiltonian
The significance of demonstrating the incapability of autoregressive models doesn't lie solely in the theorem itself. Intuitively, we already understand that autoregressive models, due to their inherent loss of information over time, are unable to generate lengthy texts. What holds importance is that through mathematical proof, we gain the knowledge necessary to establish the coherence of text generation through alternative methods.
TheoremIt is possible to associate local Hamiltonian to any auto-regressive model
proof
Let $M$ be out autoregressive model, and $s_{i_\textrm{first}},\dots,s_{i_\textrm{last}}$ our input sequence.
then the probability that the next token in the sequence is equal to $c$ is.
$$
p_c=M(s_{i_\textrm{pred}}=c|s_{i_\textrm{first}},\dots,s_{i_\textrm{last}})
$$
Through Boltzmann's equation it's possible to turn a probability distribution to some energy levels
$$
p_c=\frac 1Ze^{-\frac{E_c}{T}}\quad\textrm{with}\quad c=1\dots V
$$
Without loss of generality, we can assume $T=1$ and set the energy associated with every prediction turns out to be
$$
E_c=-\log p_c +\textrm{const} \quad\textrm{with}\quad c=1\dots V
$$
Where we can set the constant in such a way that the lowest energy state has a energy equal to zero.
We can now define a windowed Hamiltonian
$$
H_{i_\textrm{pred}}(s_{i_\textrm{first}},\dots,s_{i_\textrm{last}},s_{i_\textrm{pred}})=-\log\left[ M(s_{i_\textrm{pred}}|s_{i_\textrm{first}},\dots,s_{i_\textrm{last}})\right]+\textrm{const}
$$
And the full local Hamiltonian can now be seen as the sum of all the $H=\sum H_{i_\textrm{pred}}$ of the sequence.
The generation process of an autoregressive model can now be seen as sampling from the Boltzmann distribution given from
$$
p_\textrm{sequence}=\frac 1Z
e^{-\frac 1TH(\textrm{sequence})}
$$
So, we now know that autoregressive data generation is equivalent to sampling form the Boltzmann distribution of a local Hamiltonian (usually at $T\approx 1$), and since 1-dimensional local Hamiltonians are inherently unstable it means that autoregressive models with a finite context window are too.
As you have seen from the examples, determining whether or not an ordered phase can exists boils down to a counting problem.
- Start with the system being equal to one of the patterns stored
- Create a domain wall
- Count the number of such domain walls
- Estimate the energy gained by the system
- See if there exists a finite temperature for which the free energy decreases as the size of the domain walls goes to infinity
This can be applied to systems with very different topologies, we are now going to explore that
The most general way to consider the interaction between the elements of our system is if the interactions are represented by a graph Hamiltonian
For simplicity we are going to consider that the links of the graph are fixed in time.
Sometimes even the topology of the entire graph changes, for example before the invention of means of rapid communication each person interacted only with the people nearby thus the topology was 2-dimensional. Today, with the internet we can interact with people far away.
However, we can say that even though the interaction graph changes with time, it usually changes slowly relative to the dynamics of the time evolution of its elements.
Let G be the adjacency matrix of a graph, then a Graph Hamiltoninan H is a Hamiltonian that can be written as $$H=H*G$$ where the ($*$) operator is the element wise multiplication.
Now to see if a ordered phase can ever exist, we must generalize Peierls argument. To see if an ordered phase exists we only care how the enegry and the entropy increase when we create a domain wall
Definition: Entropy ScalingLet $H$ be a Graph Hamiltonian, and $P$ be the perimeter length, or surface area of a domain wall, as the perimeter length increases, the number of possible configurations of domain barrier increases, thus increasing the entropy of the system $\Delta S$. We say that the Entropy gained scales as $f_S$ if \[ \Delta S=O(f_S(P)) \]
Definition: Energy ScalingLet H be a Graph Hamiltonian, and $P$ be the perimeter length, or surface area of a domain wall, as the perimeter length increases, the the Higher and Lower bound of the energy gained $\Delta E$ scale as respectively $O(f_E^\textrm{high}(P))$ and $O(f_E^\textrm{low}(P))$. If $f_E^\textrm{high}=f_E^\textrm{low}\equiv f_E$ we say that the energy gained scales as $f_E$ \[ \Delta E=O(f_E(P)) \]
Once we know how the entropy and the energy scale, we know if there is a ordered phase
TheoremIf $O(f_S)=O(f_E)$ there exists a ordered phase
proof
Let's define $O(f)=O(f_S)=O(f_E)$, the change in Free energy is now $$ \Delta F= \Delta E -T\Delta S=\lim_{P\to \infty}O(f(P))-TO(f(P)) $$ If we now do $\lim_{T\to0}$ the term on the right disappears, therefore the creation of a domain wall increases the free energy and so a coherent phase is favored
This means that we don't really care about the exact formula for $E(P)$ and $S(P)$, but only on how they scale as $P\to \infty$, so we can rule out some details that can lead to complications, for example the number of stored patterns
TheoremLet $H$ be a Graph Hamiltonian with $N>1$ stored patterns. At thermal equilibrium, the ability to converge to a ordered phase doesn't depend on $N$
proof
The change in entropy due to the creation of a domain barrier can always be written as $$ \Delta S= \log\left[ (N-1)N_\textrm{barriers}\right]=\log N_\textrm{barriers} + \log (N-1) $$ Where $N_\textrm{barriers}$ is the number of barriers of a certain shape. In the thermodynamic limit, the term proportional to the number of barriers increases, while the one proportional to the number of patterns stored stays constant, therefore can be ignored as it doesn't change the entropy scaling
The importance of this last theorem is that, since the number and the shape of stored pattern doesn't affect the thermodynamics of the problem we might as well stick with a system with just 2 ground state equal to all spin ups and all spin downs. Like in the Ising Model!
We are also go one step furter we can also show that we don't really care on how strong, complicated the interaction are, and neither on how big the interaction windows are.
Let $H=\sum_i H_i$, if there exists two energies $E_\textrm{max},E_\textrm{min}$ which are the biggest and smallest non-zero energy level of all the windowed Hamiltonians $H_i$. At thermal equilibrium, the ability to converge to a ordered phase does not depend from the energy levels and the window sizes
proof
Let $\mathcal W$ be the biggest window size, and 1 the smallest window size of any $H_i$, and let $P$ be the perimeter length of our domain wall. The energy gain by creating such a domain wall is bounded by $$ P E^\textrm{min}\le\Delta E\le \mathcal W PE^\textrm {max} $$ In both cases we have that $$ E=O(P) $$
This means that, even if we have a really complicated local Hamiltonian, with large window sizes, large vocabulary size and many patterns stored, we can just look at a simple next-neighbour Ising model to see if we have a coherent phase
In this section we saw how the only thing that matters to determine if a system can be capable of self organizing at thermal equilibrium is the topology of the system.
This also means that to see if a system has the required topology to have an ordered phase you need to make sure that a topologically equivalent Ising model has an ordered phase.
In all the theorems we saw, we assumed that the Free energy is minimized. This is true at thermal equilibrium, however for some systems the time it can take to reach thermal equilibrium can be larger than the age of the universe.
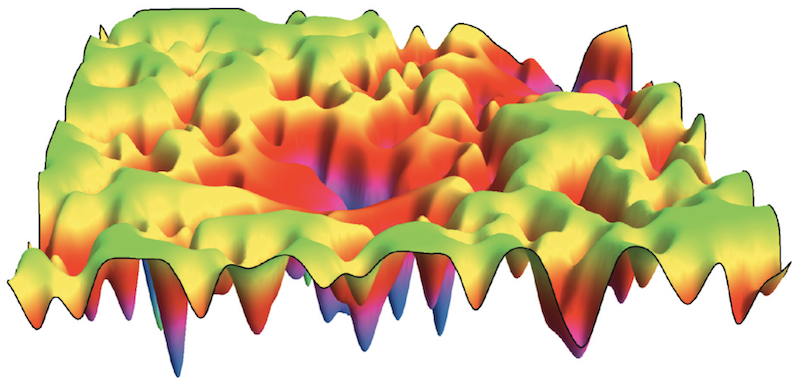
This usually happens when the energy landscape is rugged. Essentially the system stays trapped in a local minima before it ever gets the chance to get to one of the global minima. In the rare occurrence that the system manages to escape the local minimum it will most likely go to another local minimum.
When a system is like this we say that it is a spin-glass system
A spin glass system is a type of physical system that exhibits what's called "quenched disorder." This disorder arises due to random couplings, denoted as $\theta$ among the different degrees of freedom within the system, which are represented by the variable $s$. The disorder is explicitly incorporated into the Hamiltonian of the system, and is completely specified by its probability distribution, $p(\theta) d\theta$.
$$
H=H(\theta,s)
$$
One of the most well-known examples of such a system is the Edwards-Anderson model
But how can we make sure that our self organizing system behaves more like an Ising model, and not like a completely disordered spin glass? For Hopfield models people have figured it out.
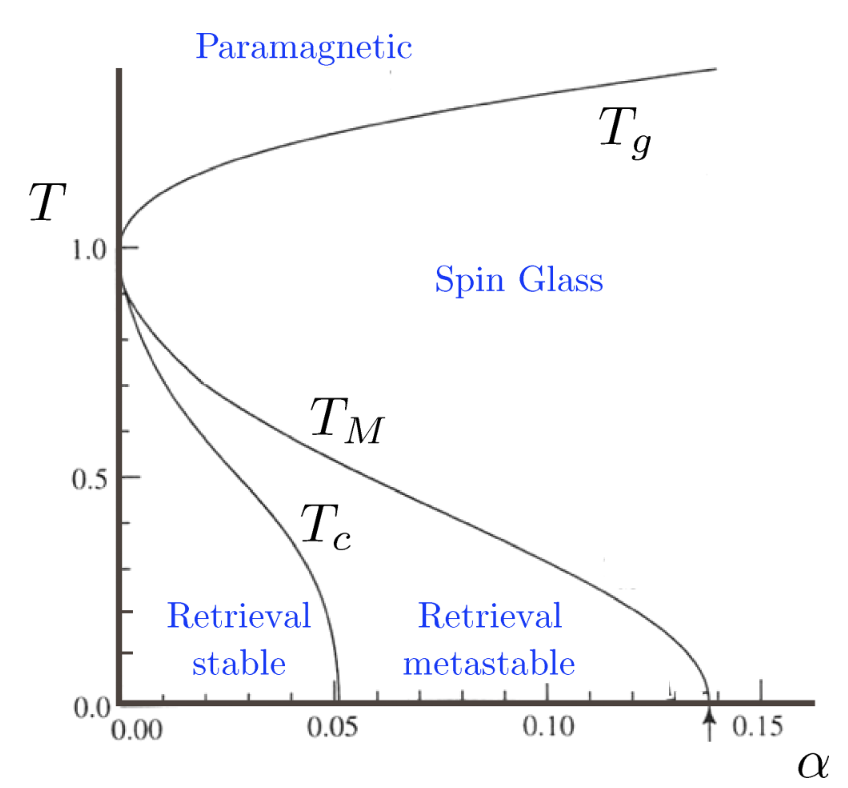
Courtesy of
An Hopfield model with one pattern stored is mathematically equivalent to the Ising model.
As you add more and more patterns it starts being more and more difficult for the system to converge to any given pattern, until it can't take it no more and it becomes glassy.
But how many patterns can our system have before it becomes glassy?
The statistics of this system have been extensively studied in the literature
It has been shown that the total number of patterns N that it is possible to store in this kind of memory is $N\approx 0.14\times P$. This estimate assumes that the patterns are statistically independent. For real life data this is usually not true as the patterns are hardly ever statistically independent, so it should be taken as an upper bound.
Studying the phase diagram rigorously can be challenging, but there are some less rigorous ways that are good enough and are much easier to generalize.
In
Let $H$ be a dense Hopfield network described by the following Hamiltoninan
$$
H=-\sum_p^N F\left(\sum_i X^p_is_i \right)
$$
Where $X^p$ is the $p$-th saved pattern.
If $F(x)=x^n$ with $n$ even the storage capacity increases with $L$ as $\alpha_n L^{n-1}$, where $\alpha_n$ is a constant dependent on $n$ and the Hamiltonian can be re-written as
outline of the proof
This is not the full proof, as that can be found in the original paper
We need to estimate the probability that at least one of the patterns is unstable
- Take with a system with $N$ random indipendently sampled patterns saved $\{X^p\}_{p\in \{1,\dots,N\}}$
- Choose as a starting configuration equal to one of the patterns saved $s_i=X^q$
- To see if the pattern saved is a local minimum, perturb the system by flipping one bit. If the energy decreases ($\Delta E < 0$), then its not a local minimum $$ \Delta E = \sum_{p}^NF\left( X^p_iX^q_i+\sum_j^D X^p_iX^q_i \right)-\sum_{p}^NF\left( -X^p_iX^q_i+\sum_j^D X^p_iX^q_i \right) $$
- Evaluate the mean $\langle \Delta E \rangle$ and the standard deviation $\Sigma^2=\langle \Delta E^2\rangle - \langle \Delta E\rangle^2$ of the change in energy over all the possible starting configurations $\{X^p\}_{p\in \{1,\dots,N\}}$
- Estimate the probability that the energy change is negative by assuming that the probablity distribution of $\Delta E$ is a gaussian of mean $\langle \Delta E \rangle$ and the standard deviation $\Sigma^2$ $$ P_\textrm{error}=\int_{\Delta E}^\infty\frac 1{\sqrt{2\pi \Sigma^2}}e^{-\frac{x^2}{2\Sigma^2}}dx $$
Similarly, in
Their proof is more rigorous, but the main idea is the same.
While these techniques are effective in increasing the memory capacity of the Hopfield network, each spin effectively interacts with every other spin. What we want is a system that is capable of self-organizing with just local interactions.
Let's define a generalized Hopfield Network where all the interactions are local.
Definition: Local Hopfield Network
The Hamiltonian of a windowed Hopfield networks is a sum over many Hopfield networks, each of which interacts inside its own window
$$
H=-\sum_j^L\sum_p^NF\left(
\sum_{\langle i,j\rangle}X^p_i\sigma_i
\right)
$$
If $F(x)=x^n$ or some other polinomial of $n$-th grade, the Hamiltonian above can be written as
$$
H=-\sum_{\langle i_1,\dots,i_n\rangle}W_{i_1,\dots,i_n}\sigma_{i_1}\dots\sigma_{i_n}
$$
Where $\sum_{\langle i_1,\dots,i_n\rangle}$ means that we are summing over all possible combinations of $n$ spins that are inside the same window of interaction.
A nice way to imagine local Hopfield network is as a patchwork of several overlapping Hopfield networks
Previously we have already seen a simulation of a local Hopfield Network with pairwise interactions.
Now that all interaction are inside a certain window, how does it change the number of stored patterns? Weirdly the memory capacity of local Hopfield network does not depend on the total number of elements, instead it is only dependent on the window size of the interactions.
TheoremThe memory capacity of a local Hopfield network with a window size equal to $\mathcal W$ is equal to the memory capacity of a standard Hopfield network with $\mathcal W$ elements.
Proof
Similarly to the theorems in
The difference in energy is equal to
$$
\Delta E=\sum_{\langle j,k\rangle}\sum_p^N
F\left(X^p_kX^q_k+
\sum_{\langle i,j\rangle\neq k}X^p_iX^q_i
\right)-
F\left(-X^p_kX^q_k+
\sum_{\langle i,j\rangle\neq k}X^p_iX^q_i
\right)
$$
The reason why the first summation is only for the spins $j$ neighboring $k$ is because only Hamiltonian windows that have the spin $k$ inside them are direcly influenced by the spin flip.
To make the calculations easier, we are going to define the local change in energy, which by how much the Hamiltonian window centered in $j$ changes his energy when the spin $k$ is flipped.
$$
\Delta E_\textrm{loc}(j)\equiv
\sum_p^N
F\left(X^p_kX^q_k+
\sum_{\langle i,j\rangle\neq k}X^p_iX^q_i
\right)-
F\left(-X^p_kX^q_k+
\sum_{\langle i,j\rangle\neq k}X^p_iX^q_i
\right)
$$
We can now write the total difference in energy as
$$
\Delta E=\sum_{\langle j,k\rangle}\Delta E_\textrm{loc}(j)
$$
When averaging over all the possible patterns $\{X^p\}_{p\in\{1,\dots,N\}}$ the $j$ dependence goes away.
This means that the average energy change of the local Hamiltonian is
$$
\left \langle \Delta E \right\rangle = \sum_{\langle j,k\rangle}
\left \langle \Delta E \right\rangle_\textrm{loc}=W \left \langle \Delta E \right\rangle_\textrm{loc}
$$
Now we calculate the variances, first the change in energy can be written as
$$
\Delta E^2=\sum_{\left \langle j_1,k \right\rangle} \sum_{\left \langle j_2,k \right\rangle}\Delta E_\textrm{loc}(j_1)\Delta E_\textrm{loc}(j_2)
$$
Now we calculate the average of the term inside the sum.
When we flip a bit in one window, the change in energy in the other window will be close to it.
$$
\Delta E_\textrm{loc}(j_2)=\Delta E_\textrm{loc}(j_1) + \delta
$$
Where $\delta$ is a random variable independent from $\Delta E_\textrm{loc}(j_1)$
Since on average the energy change of the window centered in $j_1$ is the same as the one centered in $j_2$
$$
\left \langle \Delta E_\textrm{loc}(j_1)\right \rangle=\left \langle \Delta E_\textrm{loc}(j_2)\right \rangle
$$
we have that $\left \langle \delta \right \rangle=0$
This means that
$$
\begin{split}
\left \langle \Delta E_\textrm{loc}(j_1)\Delta E_\textrm{loc}(j_2)\right \rangle=&\left \langle \Delta E_\textrm{loc}^2(j_1)\right \rangle + \left \langle \Delta E_\textrm{loc}(j_1)\delta\right \rangle =\\
=&\left \langle \Delta E_\textrm{loc}^2\right \rangle+\left \langle \Delta E_\textrm{loc}(j_1)\right \rangle\left \langle \delta\right \rangle=\\
=&\left \langle \Delta E^2_\textrm{loc}\right \rangle
\end{split}
$$
Where from the first to the second row we have used the fact that $\delta$ is independent from $\Delta E_\textrm{loc}(j_1)$, and form the second to the third row we have used the fact that $\left \langle \delta \right \rangle =0$.
Therefore equation $\Delta E^2$ becomes
$$
\left \langle \Delta E^2\right \rangle=W^2\left \langle \Delta E^2_\textrm{loc}\right \rangle
$$
and the variance is
$$
\Sigma^2=W^2\left(\left \langle \Delta E^2_\textrm{loc}\right \rangle - \left \langle \Delta E_\textrm{loc}\right \rangle ^2\right)=W^2\Sigma_\textrm{loc}
$$
Suppose that the probability distribution is a Gaussian with mean $\left \langle \Delta E\right \rangle$ and variance $\Sigma^2$. Then the probability of making an error is the probability that after the spin flips, the energy of the system decreases.
$$
\begin{split}
P=&\int_{\Delta E}^\infty\frac 1{\sqrt{2\pi\Sigma^2}}e^{-\frac{x^2}{2\Sigma^2}}dx=\\
=& \int_{W\Delta E_\textrm{loc}}^\infty\frac 1{\sqrt{2\pi W^2\Sigma_\textrm{loc}^2}}e^{-\frac{x^2}{2W^2\Sigma_\textrm{loc}^2}}dx=\\
=&\int_{\Delta E_\textrm{loc}}^\infty\frac 1{\sqrt{2\pi \Sigma_\textrm{loc}^2}}e^{-\frac{z^2}{2\Sigma_\textrm{loc}^2}}dz=\\
=&P_\textrm{loc}
\end{split}
$$
Where in the last passage we defined $z=x/W$.
This means that a Hopfield network with an energy function that is the sum of several overlapping sub-Hopfield networks with window size of $W$ has a storage capacity of any given sub-network
This is the main result of the paper: It shows us how complex and intelligent can be a self-organizing system made of just local interactions (assuming that the topology of the system allows for an ordered phase to exist)
It is crucial to bear in mind that these represent some of the essential prerequisites.
Similar to how possessing Turing Completeness does not guarantee intelligence, having an ordered phase in a system does not automatically imply that the output will be actually coherent and meaningful.
We now possess all the necessary elements to ascertain whether a system can ever exhibit the capacity to generate data coherently.
- Select a topology of communication of the cells that is equivalent to an Ising model that has an ordered phase
- Make sure that the system in not bottlenecked by the memory capacity (either by having a large enough window size and a large enough number of trainable parameters)
We want to see if a transformer that has an attention matrix with the topology of a tree can ever generate text.
-
Since the Ising model on the tree does have an ordered phase
,the possibility of generating an infinitely long, coherent text is not constrained by the topology - The bottleneck provided by the memory capacity can be widened by increasing the window size and the number of parameters
Experiments
Recently a paper has come out that uses a tree-like attention structure
However, it is unclear if this specific experiment resulted in a model that is actually capable of retrieving any information inside that effective context of 1 billion tokens.
Let's start with a system inspired by how the brain is thought to work.
One can naively say that the way the state of the brain at the time $t$ depends from the state $t-1$
However we (and some other organisms) also augment our finite memory by deliberately interacting with the environment, this way we are able to remember stuff for much longer.
For example when you go shopping, you write down what you have to buy on a piece of paper, this is because information stays there longer and more reliably than if you try to remember it.
This example also raises an interesting observation: When you read your shopping list, you effectively "interact" with your past self though interacting with a piece of paper

This sort of thing happens all the time, our brain constantly interacts with the surrounding environment so much that it is impossible to study the brain independently from the environment
We humans are not the only ones engaged in this intricate dance of information exchange with their environment. Nature has its own fascinating mechanisms for information storage and communication, one of which is known as "stigmergy"
Now let's look at the brain+environment system from a more formal point of view.
Let $B_t$ be the state of the brain at the time $t$ and $E_t$ the state of the environment, we can say that the way they evolve is ruled by a set of equations like this. $$ \begin{cases} B_{t+1}=f_B(B_t,E_t)\\ E_{t+1}=f_E(B_t,E_t) \end{cases} $$ Note that this is simply an autoregressive model made of two coupled autoregressive models, however we can assume that the environment is capable of holding on to information for longer.
We can simplify a system like this by assuming that both the brain and the environment have only two possible states: 0 or 1.
We can think of it as two spin chains with different coupling constants $J_E$ and $J_B$, since the environment has a much bigger coherence length we can assume that $J_E\gg J_B$. We also assume that there is a coupling constant $J_C$ that couples the neighboring spins of the two chains.
The Hamiltonian becomes:
$$
H = -J_E\sum_t E_tE_{t+1} - J_B\sum_t B_{t}B_{t+1} - J_C\sum_t E_tB_{t}
$$
For example at $T\approx 1$ if you set $J_E \approx 5$ the coherence length of the environment is going to be large. You can also see that if you set the other two coupling constants relatively small $J_B, J_C\approx 1$ you are going to see that the value of the brain state $B_i$ will oscillate, but it is going to be most of the time equal to the value of the environment $E_t$.
If you want to decouple the brain with the environment just set $J_C=0$
Thus, what effectively happens is that when $J_C$ is not too small, the coherence length of the brain chain becomes equal to the one of the environment.
A mathematical argument on why the coherence length of the two chains coupled chains tend to match
Lets take the Hamiltonian for our brain + environment system and assume that the environment has a much longer coherence lenght than the brain. We can now focus our attention inside one of the continous domains where the environment is constant with a value of $E$. The Hamiltonian becomes $$ H=-J_b\sum_tB_tB_{t+1} - J_cE\sum_t B_t $$ This is equivalent to the Hamiltonian for the 1D Ising model with an external magnetic field, since it is exactly solvable it is possible to evaluare the average value of $B=\langle B_t\rangle$ $$ B=\frac {\sinh (J_cE/T)}{\sqrt{\sinh^2(J_cE/T) + e^{-4J_b/T}}} $$ And we have that the lower the temperature is, the more the chain aligns with the environment value.
Experiments
Systems like this made from a model with limited context length + an external environment can be found in the language modeling + reinforcement learning literature. One that I particularly like is Voyager
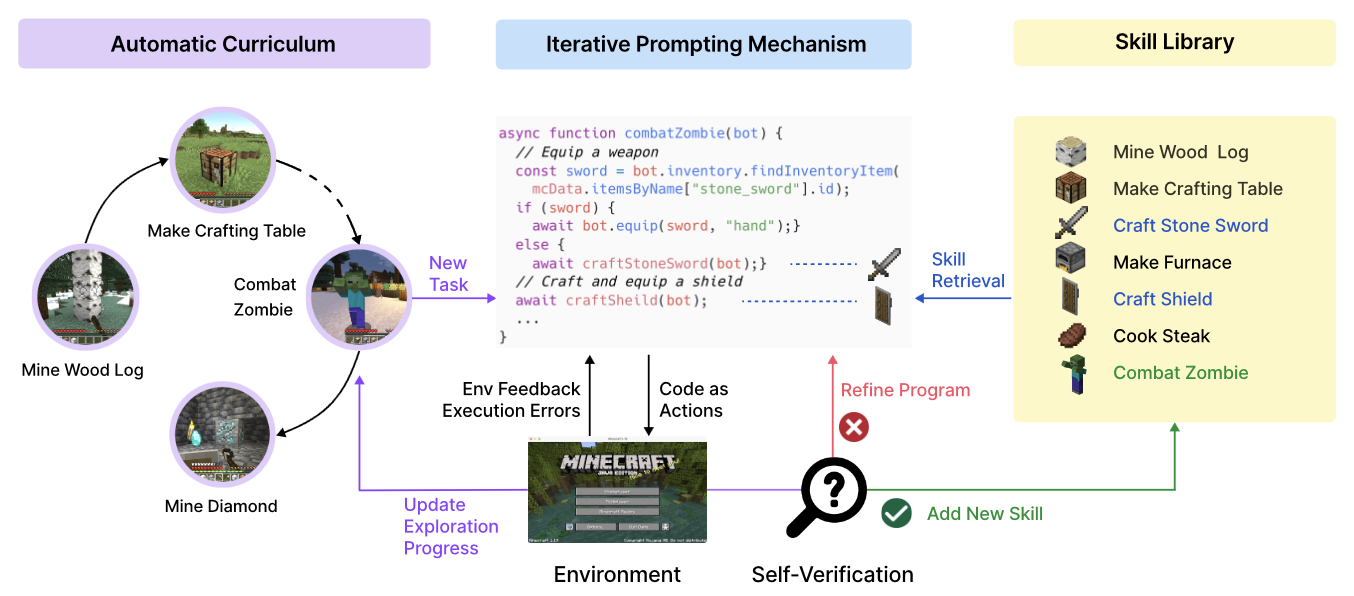
In this paper the "brain" is a large language model (GPT-4), and it is able to interact with both the game world, and a code library where the LLM can both read, write and organize information.
By doing so the agent is capable of using skills and information that has been written in the distant past. This effectively increases the context length of the language model.
Overall, these examples
We have shown how the right topology for cell communication is a necessary feature for long range coherence by framing the problem of data generation as interactions of multiple sub-units.
Biological systems have long exploited self-organization and indeed possess the right topology to be able to self-organize, furthermore we showed how current NLP algorithms don't possess the needed topology and because of that are incapable of generating long and coherent text.
The same requirements needed for generating coherent text apply to agents trying to navigate a problem space by performing a series of actions, thus all the results also apply in the field of reinforcement learning if the agent has to remember past actions in order to correctly act in the future.
However, since disorder can lead to glassy dynamics, we calculated the memory capacity of self-organizing systems made only by local interactions.
We also showed how an agent with limited context (such as a transformer based LLM) can in principle be able to extend their context by deliberately interacting with the external environment and how biological organisms learned this skill to be able to retain information for a long time.